
In this Spark article, you will learn how to union two or more tables of the same schema which are from different Hive databases with Scala examples.
First, let’s create two tables with the same schema in different Hive databases. To create tables we need hive in this process, so add the required maven/Gradle dependency and enable hive support in spark configuration.
Maven Dependency
You can use supportive spark version, I have used 2.4.4
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-hive_2.12</artifactId>
<version>${spark.version}</version>
</dependency>
Create SparkSession by Enabling Hive Support
Now add enableHiveSupport while creating SparkSession object, so that we can create Hive databases and tables using Spark.
val spark = SparkSession.builder
.appName("my-app")
.master("local[*]")
.enableHiveSupport()
.getOrCreate()
Create Databases and Tables with the Same schema
As our concept is to union tables of the same schema from different Hive databases, let’s create database1.table1 and database2.table2 by reading the same .csv file, so that schema is constant.
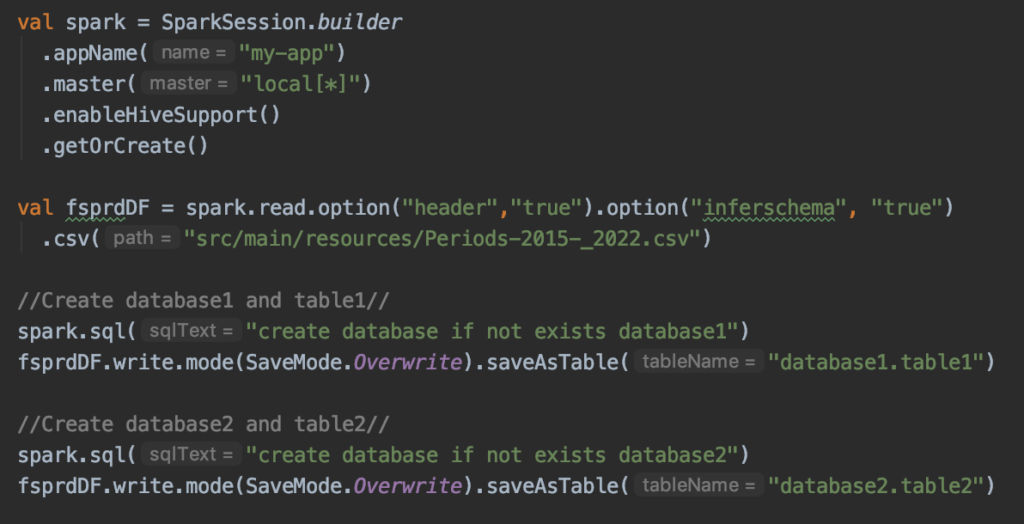
In the above code snippet, we are reading the CSV file into DataFrame and storing that DataFrame as a Hive table in two different databases.
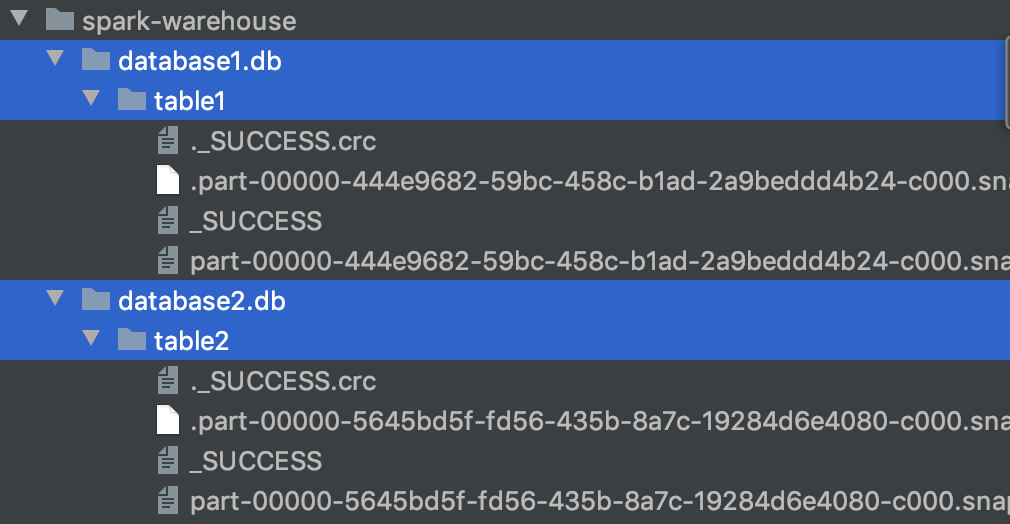
Now, we had produced table1 and table2 with same schema in different databases.
Union Tables From Different Database
Now try to union them write the result into a separate table.
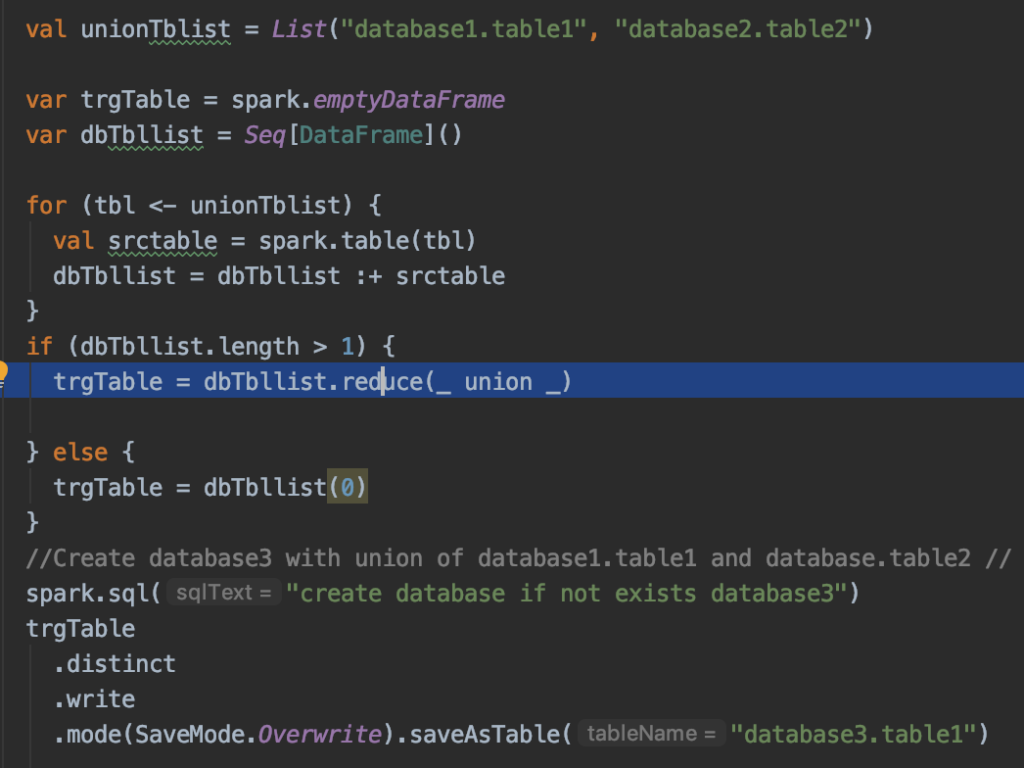
Dataframe union() – union() method of the DataFrame is used to combine two DataFrame’s of the same structure/schema. If schemas are not the same it returns an error.
What we did here is
- Get a list of combinations of tables and their database name.
- Create an empty DataFrame and empty List of the type data frame
- Now loop over the database.tableName list and create a data frame for each
- Collect all the data frames and append it to
List[DataFrame]we created earlier. - Reduce the method on the List[DataFrame] with the accumulator as
UNION. We used to reduce here because reduction will always return the accumulator you eventually changed. - Finally, we have the DataFrame which is a combination of a table with the same schema from multiple databases.
- We can create a table on top of this final data Frame.
Below is the complete example:
val spark = SparkSession.builder
.appName("my-app")
.master("local[*]")
.enableHiveSupport()
.getOrCreate()
//Reading csv file.
val fsprdDF = spark.read.option("header","true").option("inferschema", "true")
.csv("src/main/resources/Periods-2015-_2022.csv")
//Create database1 and table1
spark.sql("create database if not exists database1")
fsprdDF.write.mode(SaveMode.Overwrite).saveAsTable("database1.table1")
//Create database2 and table2
spark.sql("create database if not exists database2")
fsprdDF.write.mode(SaveMode.Overwrite).saveAsTable("database2.table2")
//UNION Operation
val unionTblist = List("database1.table1", "database2.table2")
var trgTable = spark.emptyDataFrame
var dbTbllist = Seq[DataFrame]()
for (tbl 1) {
trgTable = dbTbllist.reduce(_ union _)
} else {
trgTable = dbTbllist(0)
}
//Create database3.table1 with union of database1.table1 and database.table2
spark.sql("create database if not exists database3")
trgTable
.distinct
.write
.mode(SaveMode.Overwrite).saveAsTable("database3.table1")
}
That’s it!
Hope it helps. :)
keep learning and keep growing.
Related Article
- Spark DataFrame Union and Union All
- What is Apache Spark and Why It Is Ultimate for Working with Big Data
- Spark Using Length/Size Of a DataFrame Column
- Spark Trim String Column on DataFrame
- Spark Get DataType & Column Names of DataFrame
- Spark Get the Current SparkContext Settings
- Hive Aggregate Functions (UDAF) with Examples
- Hive Relational | Arithmetic | Logical Operators
- Hive Built-in String Functions with Examples