
Let’s learn what is the difference between PySpark repartition() vs partitionBy() with examples.
PySpark repartition() is a DataFrame method that is used to increase or reduce the partitions in memory and when written to disk, it create all part files in a single directory.
PySpark partitionBy() is a method of DataFrameWriter class which is used to write the DataFrame to disk in partitions, one sub-directory for each unique value in partition columns.
Let’s Create a DataFrame by reading a CSV file. You can find the dataset explained in this article at GitHub zipcodes.csv file
import pyspark
from pyspark.sql import SparkSession
spark = SparkSession.builder.appName('SparkByExamples.com') \
.master("local[5]").getOrCreate()
df=spark.read.option("header",True) \
.csv("/tmp/resources/simple-zipcodes.csv")
df.printSchema()
#Display below schema
root
|-- RecordNumber: string (nullable = true)
|-- Country: string (nullable = true)
|-- City: string (nullable = true)
|-- Zipcode: string (nullable = true)
|-- state: string (nullable = true)
1. PySpark repartition() vs partitionBy()
Let’s see difference between PySpark repartition() vs partitionBy() with few examples. and also will see an example how to use both these methods together.
| repartition() & partitionBy() Methods |
|---|
| repartition(numPartitions : scala.Int) |
| repartition(partitionExprs : Column*) |
| repartition(numPartitions : scala.Int, partitionExprs : Column*) |
| partitionBy(colNames : _root_.scala.Predef.String*) |
1.1 repartition(numPartitions : scala.Int) Example
PySpark repartition() is a DataFrame method that is used to increase or reduce the partitions in memory and returns a new DataFrame.
newDF=df.repartition(3)
print(newDF.rdd.getNumPartitions())
When you write this DataFrame to disk, it creates all part files in a specified directory. Following example creates 3 part files (one part file for one partition).
newDF.write.option("header",True).mode("overwrite") \
.csv("/tmp/zipcodes-state")
Note: When you want to reduce the number of partitions, It is recommended to use PySpark coalesce() over repartition()
1.2 repartition(numPartitions : scala.Int, partitionExprs : Column*) Example
Using this method, we still create partitions but all records for each state end’s up in the same file.
df2=df.repartition(3,state)
df2.write.option("header",True).mode("overwrite")
.csv("/tmp/zipcodes-state")
This creates a DataFrame with 3 partitions using a hash-based partition on state column. The hash-based partition takes each state value, hashes it into 3 partitions (partition = hash(state) % 3). This guarantees that all rows with the same sate (partition key) end up in the same partition.
Note: You may get some partitions with few records and some partitions more records.
1.3 partitionBy(colNames : String*) Example
PySpark partitionBy() is a function of pyspark.sql.DataFrameWriter class that is used to partition based on one or multiple columns while writing DataFrame to Disk/File system. It creates a sub-directory for each unique value of the partition column.
Creating disk level partitioning, speeds up further data reading when you filter by partitioning column.
#partitionBy()
df.write.option("header",True) \
.partitionBy("state") \
.mode("overwrite") \
.csv("/tmp/zipcodes-state")
On our DataFrame, we have a total of 6 different states hence, it creates 6 directories as shown below. The name of the sub-directory would be the partition column and its value (partition column=value).
Note: Actual data written to disk on part files doesn’t contains partition column hence it saves some space on storage.
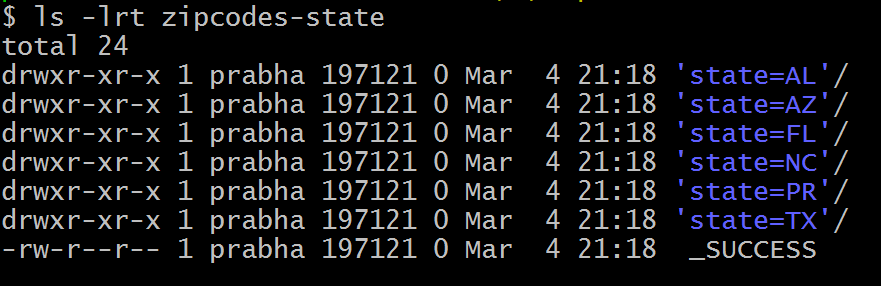
For each partition column, you could further divide into several partitions by using repartition() and partitionBy() together as explained in the below example.
#Use repartition() and partitionBy() together
dfRepart.repartition(2)
.write.option("header",True) \
.partitionBy("state") \
.mode("overwrite") \
.csv("c:/tmp/zipcodes-state-more")
repartition() creates a specified number of partitions in memory. The partitionBy() will write files to disk for each memory partition and partition column.
After running the above statement, you should see only 2 part files for each state.

Our dataset has 6 unique states, we have asked 2 memory partitions for each state, hence the above code creates a maximum total of 6 x 2 = 12 part files.
Note: Note that this may create a Data Skew if not designed right. In our dataset, total zipcodes for each US state differ in large, for example, California and Texas have many zipcodes whereas Delaware has very few, hence it creates some partitions with fewer records and some partitions with a huge number of records resulting in Data Skew (Total rows per each part file differs in large).
2. Conclusion
In this quick article, you have learned PySpark repartition() is a transformation operation that is used to increase or reduce the DataFrame partitions in memory whereas partitionBy() is used to write the partition files into a subdirectories
Happy Learning !!
Related Articles
- PySpark partitionBy() Explained with Examples
- PySpark repartition() vs coalesce() differences
- PySpark Parallelize | Create RDD
- PySpark cache() Explained.
- PySpark createOrReplaceTempView() Explained
- PySpark Read JDBC Table to DataFrame
- PySpark Read and Write SQL Server Table
- PySpark Query Database Table using JDBC