
Broadcast join is an optimization technique in the PySpark SQL engine that is used to join two DataFrames. This technique is ideal for joining a large DataFrame with a smaller one. Traditional joins take longer as they require more data shuffling and data is always collected at the driver. In order to do broadcast join, we should use the broadcast shared variable.
In this article, I will explain what is PySpark Broadcast Join, its application, and analyze its physical plan.
1. PySpark Broadcast Join
PySpark defines the pyspark.sql.functions.broadcast() to broadcast the smaller DataFrame which is then used to join the largest DataFrame. As you know PySpark splits the data into different nodes for parallel processing, when you have two DataFrames, the data from both are distributed across multiple nodes in the cluster so, when you perform traditional join, PySpark is required to shuffle the data. Shuffle is needed as the data for each joining key may not colocate on the same node and to perform join the data for each key should be brought together on the same node. Hence, the traditional PySpark Join is a very expensive operation.
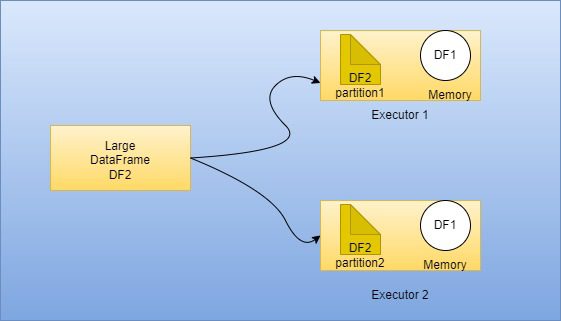
PySpark Broadcast Join is an important part of the SQL execution engine, With broadcast join, PySpark broadcast the smaller DataFrame to all executors and the executor keeps this DataFrame in memory and the larger DataFrame is split and distributed across all executors so that PySpark can perform a join without shuffling any data from the larger DataFrame as the data required for join colocated on every executor.
Note: In order to use Broadcast Join, the smaller DataFrame should be able to fit in Spark Drivers and Executors memory. If the DataFrame can’t fit in memory you will be getting out-of-memory errors. You can also increase the size of the broadcast join threshold using some properties which I will be discussing later.
2. Types of Broadcast join.
There are two types of broadcast joins in PySpark.
- Broadcast hash joins: In this case, the driver builds the in-memory hash DataFrame to distribute it to the executors.
- Broadcast nested loop join: It is a nested for-loop join. It is very good for non-equi joins or coalescing joins.
3. Configuring PySpark Auto Broadcast join.
We can provide the max size of DataFrame as a threshold for automatic broadcast join detection in PySpark. This can be set up by using autoBroadcastJoinThreshold configuration in SQL conf. Its value purely depends on the executor’s memory.
#Enable broadcast Join and
#Set Threshold limit of size in bytes of a DataFrame to broadcast
spark.conf.set("spark.sql.autoBroadcastJoinThreshold", 104857600)
#Disable broadcast Join
spark.conf.set("spark.sql.autoBroadcastJoinThreshold", -1)
The threshold value for broadcast DataFrame is passed in bytes and can also be disabled by setting up its value as -1.
4. Example of a Broadcast Join
For our demo purpose, let us create two DataFrames of one large and one small using Databricks. Here we are creating the larger DataFrame from the dataset available in Databricks and a smaller one manually.
#Create a Larger DataFrame using weather Dataset in Databricks
largeDF = spark.read
.option("header",True)
.option("inferschema",True)
.parquet("dbfs:/mnt/training/weather/StationData/stationData.parquet")
.limit(2000)
#Create a smaller dataFrame with abbreviation of codes
simpleData =(("C", "Celcius"),
("F", "Fahrenheit")
)
smallerDF = spark.createDataFrame(data = simpleData, schema = ["code", "realUnit"])
Now let’s broadcast the smallerDF and join it with largerDF and see the result.
# Perform broadast join
from pyspark.sql.functions import broadcast
largeDF.join(
broadcast(smallerDF),
smallerDF("code") largeDf("UNIT")
).show()
5. Analyze Broadcast Join
We can use the EXPLAIN() method to analyze how the PySpark broadcast join is physically implemented in the backend.
# Explain broadcast join
from pyspark.sql.functions import broadcast
largeDF.join(
broadcast(smallerDF),
smallerDF("code") largeDF("UNIT")
).explain(extended=False)
The parameter “extended=false” to the EXPLAIN() method results in the physical plan that gets executed on the executors.
Output
== Physical Plan ==
AdaptiveSparkPlan isFinalPlan=false
+- BroadcastHashJoin [coalesce(UNIT#543, ), isnull(UNIT#543)], [coalesce(code#560, ), isnull(code#560)], Inner, BuildRight, false
:- GlobalLimit 2000
: +- Exchange SinglePartition, ENSURE_REQUIREMENTS, [id=#313]
: +- LocalLimit 2000
: +- FileScan parquet [NAME#537,STATION#538,LATITUDE#539,LONGITUDE#540,ELEVATION#541,DATE#542,UNIT#543,TAVG#544] Batched: true, DataFilters: [], Format: Parquet, Location: InMemoryFileIndex(1 paths)[dbfs:/mnt/training/weather/StationData/stationData.parquet], PartitionFilters: [], PushedFilters: [], ReadSchema: struct<NAME:string,STATION:string,LATITUDE:float,LONGITUDE:float,ELEVATION:float,DATE:date,UNIT:s...
+- BroadcastExchange HashedRelationBroadcastMode(ArrayBuffer(coalesce(input[0, string, true], ), isnull(input[0, string, true])),false), [id=#316]
+- LocalTableScan [code#560, realUnit#561]
Notice how the physical plan is created in the above example.
- First, It read the parquet file and created a Larger DataFrame with limited records.
- Then,
BroadcastHashJoinis performed between the smallerDF and LargerDF using the condition provided. - Even if the smallerDF is not specified to be broadcasted in our code, Spark automatically broadcasts the smaller DataFrame into executor memory by default.
6. Conclusion
- PySpark Broadcast joins cannot be used when joining two large DataFrames. Broadcast join naturally handles data skewness as there is very minimal shuffling. The limitation of broadcast join is that we have to make sure the size of the smaller DataFrame gets fits into the executor memory.
Related Articles
- PySpark Broadcast Variable
- PySpark lag() Function
- PySpark Random Sample with Example
- PySpark reduceByKey usage with example
- Pyspark – Get substring() from a column
- Show First Top N Rows in Spark | PySpark
- PySpark Create DataFrame from List
- PySpark Concatenate Columns
- PySpark Refer Column Name With Dot (.)