
Apache Spark & PySpark supports SQL natively through Spark SQL API which allows us to run SQL queries by creating tables and views on top of DataFrame.
In this article, we shall discuss the types of tables and view available in Apache Spark & PySpark. Apache Spark is a distributed data processing engine that allows you to create three main types of non-temporary cataloged tables EXTERNAL, MANAGED, and different types of VIEW.
VIEW is used for persistent views, whereas EXTERNAL and MANAGED are used for tables.
Table of contents
1. What is a Table?
Like any RDBMS table, Spark Table is a collection of rows and columns stored as data files in object storage (S3, HDFS, Azure BLOB e.t.c). There are mainly two types of tables in Apache spark (Internally these are Hive tables)
- Internal or Managed Table
- External Table
Related: Hive Difference Between Internal vs External Tables
1.1. Spark Internal Table
An Internal table is a Spark SQL table that manages both the data and the metadata.
- Data is usually gets stored in the default Spark SQL warehouse directory.
- Metadata gets stored in a meta-store of relational entities (including databases, Spark tables, and temporary views) and can be accessed through an interface known as the “data” in Databricks.
- A globally managed table is available across all clusters.
- When we drop the internal table both data and metadata get dropped, meaning that we will neither be able to query the table directly nor retrieve data from it.
Let’s create an internal table and look at the table properties in Databricks.
//Creates a Delta table in default SPARK SQL Warehouse Directory
CREATE TABLE IF NOT EXISTS internal_table (id INT, FirstName String, LastName String);
INSERT INTO internal_table values (1,"John", "Smith");
SELECT * FROM internal_table;
//output:
id|FirstName|LastName
1|John|Smith
Above we have created a managed Spark table (internal_table) and inserted a few records into it. Now let us look at the table properties using DESCRIBE command
//Describe table
DESCRIBE EXTENDED internal_table
Output:
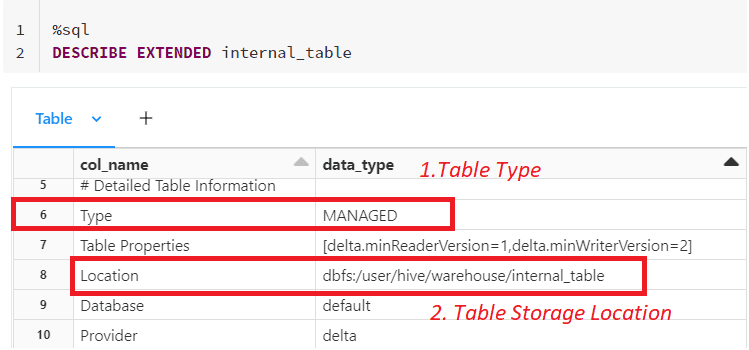
In the table properties, we see the type of the Spark table as “MANAGED” and the data of the table gets stored in the default Spark SQL Warehouse path i.e /user/hive/warehouse/internal_table
Note: If we run the drop command on this internal table, Both Data including the Location and Metadata of the table from database objects get removed.
1.2. Spark External Table
An External table is a SQL table that Spark manages the metadata and we control the location of table data.
- We are required to specify the exact location where you wish to store the table or, alternatively, the source directory from which data will be pulled to create a table.
- Metadata gets stored in a meta-store of relational entities (including databases, tables, and temporary views) and can be accessed through an interface known as the “data” in Databricks.
- External tables are only accessible by the clusters that have access to the table storage system.
- Dropping an external table will only drop table details from the Spark Metastore, but the underlying data remains as it is in its directory.
Let us create an external Spark table with a storage location specified while creating.
//Create a Delta table under storage location "/user/tmp/external_table"
CREATE TABLE IF NOT EXISTS external_table (id INT, FirstName String, LastName String) LOCATION '/user/tmp/external_table';
INSERT INTO external_table values (1,"John", "Smith");
SELECT * FROM external_table;
//output:
id|FirstName|LastName
1|John|Smith
Above we have created an external Spark table (external_table) with a storage location specified and inserted a few records into it. Now let us look at the table properties using DESCRIBE command
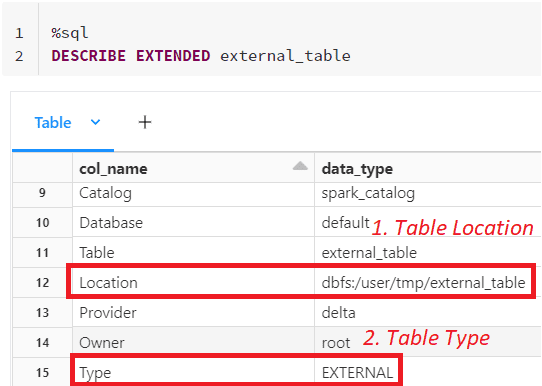
In the table properties, we see the Type of the Spark table as “EXTERNAL” and the data of the table gets stored in the location specified while creating the Spark SQL table i.e “/user/tmp/external_Table“.
Note: If we run the drop command on this External table, only the Metadata of the table object from database objects gets removed. Data remains as it is.
2. What is a View?
A Spark view is more like a virtual table with no physical data available. we have mainly three types of views in Apache Spark
- Temporary View.
- Global Temporary View.
- Global Permanent View.
2.1. Temporary View
TEMPORARY Spark views are SparkSession scoped, they are only available to the session that created them and is dropped automatically as soon as the session ends.
These Spark views are not accessible by any other sessions or clusters. Also not get stored in the Metastore.
Related: Spark createOrReplaceTempView() Explained
Syntax:
//Syntax for creating a temp view
CREATE OR REPLACE TEMP VIEW viewName AS (select expression from a table);
Example:
//Creating a temp view
CREATE OR REPLACE TEMP VIEW tempView AS SELECT * FROM internal_table;
SELECT * FROM tempView;
//output:
id|FirstName|LastName
1|John|Smith
Above we have created a temporary Spark view using the internal_table that we created earlier.
2.2. Global Temporary View
As Temporary views in Spark SQL are session-scoped, if we want temporary views to be able to be shared among all sessions and keep alive until the Spark application terminates, you can create a global temporary view.
- These are Spark application scoped.
- These Spark views can be shared across Spark sessions.
- The global temporary view is tied to a system-preserved database global_temp.
Syntax:
//Syntax for creating a Global temp view
CREATE OR REPLACE TEMP GLOBAL VIEW viewName AS (select expression from a table);
Examples:
//Syntax for creating a Global temp view
CREATE OR REPLACE GLOBAL TEMP VIEW globalTempView AS SELECT * FROM internal_table;
Note: The global temporary view remains accessible as long as the application is alive.
2.2. Global Permanent View
Global Permanent views are created by persisting the data.
- These are permanent views.
- Its view definition is stored in the Metastore of Spark.
- These Spark views can be created on both internal and external tables. But can not be created on top of Temporary views and DataFrames.
- Currently, it is supported only using Spark SQL.
Syntax:
//Syntax for creating a Global Permanent views
CREATE OR REPLACE VIEW viewName AS (select expression from a table);
Example:
//Syntax for creating a Global Permanent views
CREATE OR REPLACE VIEW globalPermanentView AS select * from a internal_table;
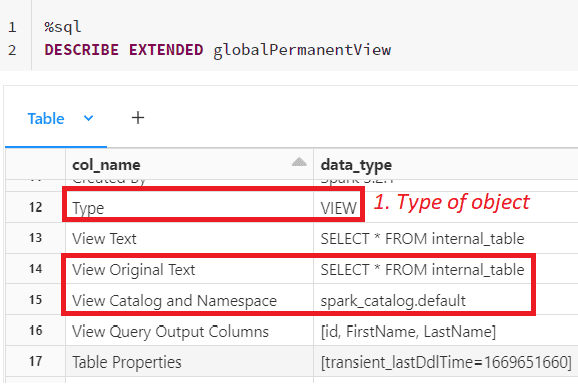
In the Spark view properties, we see the Type as “VIEW” and the view definition under view text.
3. Conclusion
In Apache Spark or PySpark, we have these options in tables and views so that we can use each of its features based on our application needs.
We create Internal tables during
- When we are much worried about data reproducibility.
- When we want the Spark to manage both data and metadata.
- When we want to store data temporarily before writing into a final location.
- When we don’t have an external fault-tolerant storage system.
We create an External Table during.
- When we don’t want to manage the schema.
- When we want to share our data across multiple applications.
- When we want to secure our data even after dropping the table.