
In this article let us discuss the Kryoserializer buffer max property in Spark or PySpark. Before deep diving into this property, it is better to know the background concepts like Serialization, the Type of Serialization that is currently supported in Spark, and their advantages over one other.
1. What is serialization?
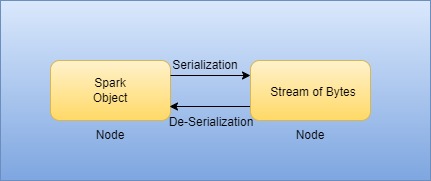
Serialization is an optimal way to transfer a stream of objects across the nodes in the network or store them in a file/memory buffer. The max buffer storage capacity depends on the configuration setup. As spark process the data distributedly, data shuffling across the network is most common. If the way of the transfer system is not handled efficiently, we may end up with many problems like
- High Memory consumption
- Network Bottleneck
- Performance Issues.
2. Types of Spark Serialization techniques
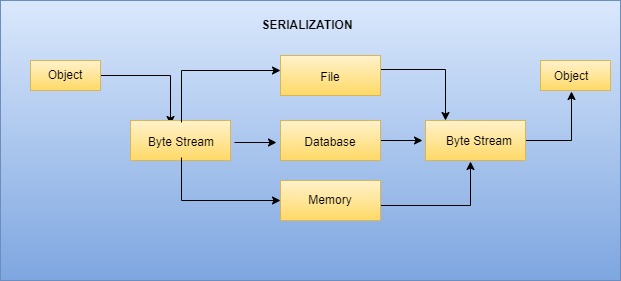
There are mainly three types of Serialization techniques that are available in spark. By changing these techniques you may get performance improvements on your Spark jobs. Even though the Spark creators did not reveal the internal working of these techniques, let us have a high-level understanding of each of them.
- Java Serialization:
- This is the default serialization technique in Spark for Java and Scala Objects.
- Supports only RDD and DataFrames.
- Datasets are not supported in this method.
- Less performative when compared to Kyro.
- Kyro Serialization:
- This technique is faster and more efficient.
- The only reason Kryo is not set to default is that it requires custom registration.
- It takes less time for the conversion of objects into bytes stream and vice-versa.
- It occupies less space.
- It is not natively supported to serialize to the disk.
- Encoders:
- This serialization is the default for Datasets.
- It doesn’t support RDD and DataFrames.
- These are more efficient and performative.
3. Configurations for Kryoserializer
Even though Java Serialization is flexible, it is relatively slow and hence we should use the Kyro serialization technique which is an alternate serialization mechanism in Spark or PySpark. Now let us see how to initialize it and its properties.
3.1 Setup Spark Kryoserializer
In the below Spark example, I have initialized the configuration to Spark using SparkConf and updated the Spark Serializer to use Kyroserializer, and config values are used to create SparkSession.
//Initialize Spark Configuration
val conf = new SparkConf()
//Set spark serializer to use Kyroserializer
conf.set( "spark.serializer",
"org.apache.spark.serializer.KyroSerializer")
//Initialize Spark Session
val spark = SparkSession.builder().config(conf)
.master("local[3]")
.appName("SparkByExamples.com")
.getOrCreate();
3.2 Properties of Spark Kryoserializer
As Serialization is the process of converting an object into a sequence of bytes which can then be:
- Stored to disk
- Saved to a database
- Sent over the network
There are a few Spark properties that help to adopt Kryoserializer as per our requirement which among them is the buffer property.
| Property | Default Value | Usage |
|---|---|---|
spark.kryoserializer.buffer | 64K | Initial size of Kryo’s serialization buffer. Note that there will be one buffer per core for each worker. This buffer will grow up spark.kryoserializer.buffer.max.mb if needed. |
spark.kryoserializer.buffer.max | 64m | The maximum allowable size of Kryo serialization buffer. This must be larger than any object you attempt to serialize. Increase this if you get a “buffer limit exceeded” exception inside Kryo. |
4. Conclusion
For any high network-intensive Spark or PySpark application, it is always suggested to use the Kyro Serializer and set the max buffer size with the right value. Since Spark 2.0, the framework had used Kyro for all internal shuffling of RDDs, DataFrame with simple types, arrays of simple types, and so on. Spark also provides configurations to enhance the Kyro Serializer as per our application requirement.
Related Articles
- What is spark.driver.maxResultSize?
- Spark/Pyspark Application Configuration
- Spark Web UI – Understanding Spark Execution
- Spark SQL Performance Tuning by Configurations
- Spark – Stop INFO & DEBUG message logging to console?
- Read JDBC Table to Spark DataFrame
- Testing Spark locally with EmbeddedKafka: Streamlining Spark Streaming Tests
- Spark Kryoserializer buffer max
- Spark with SQL Server – Read and Write Table
- reduceByKey vs groupByKey vs aggregateByKey vs combineByKey in Spark
- Reduce Key-Value Pair into Key-list Pair
- Spark Extract Values from a Row Object