
PySpark provides two transform() functions one with DataFrame and another in pyspark.sql.functions.
- pyspark.sql.DataFrame.transform() – Available since Spark 3.0
- pyspark.sql.functions.transform()
In this article, I will explain the syntax of these two functions and explain with examples. First, let’s create the DataFrame.
# Imports
from pyspark.sql import SparkSession
# Create SparkSession
spark = SparkSession.builder \
.appName('SparkByExamples.com') \
.getOrCreate()
# Prepare Data
simpleData = (("Java",4000,5), \
("Python", 4600,10), \
("Scala", 4100,15), \
("Scala", 4500,15), \
("PHP", 3000,20), \
)
columns= ["CourseName", "fee", "discount"]
# Create DataFrame
df = spark.createDataFrame(data = simpleData, schema = columns)
df.printSchema()
df.show(truncate=False)
1. PySpark DataFrame.transform()
The pyspark.sql.DataFrame.transform() is used to chain the custom transformations and this function returns the new DataFrame after applying the specified transformations.
This function always returns the same number of rows that exists on the input PySpark DataFrame.
1.1 Syntax
Following is the syntax of the pyspark.sql.DataFrame.transform() function
# Syntax
DataFrame.transform(func: Callable[[…], DataFrame], *args: Any, **kwargs: Any) → pyspark.sql.dataframe.DataFrame
The following are the parameters:
func– Custom function to call.*args– Arguments to pass to func.*kwargs– Keyword arguments to pass to func.
1.2 Create Custom Functions
In the below snippet, I have created the three custom transformations to be applied to the DataFrame. These transformations are nothing but Python functions that take the DataFrame apply some changes and return the new DataFrame.
- to_upper_str_columns() – This function converts the CourseName column to upper case and updates the same column.
- reduce_price() – This function takes the argument and reduces the value from the fee and creates a new column.
- apply_discount() – This creates a new column with the discounted fee.
# Custom transformation 1
from pyspark.sql.functions import upper
def to_upper_str_columns(df):
return df.withColumn("CourseName",upper(df.CourseName))
# Custom transformation 2
def reduce_price(df,reduceBy):
return df.withColumn("new_fee",df.fee - reduceBy)
# Custom transformation 3
def apply_discount(df):
return df.withColumn("discounted_fee", \
df.new_fee - (df.new_fee * df.discount) / 100)
1.3 PySpark Apply DataFrame.transform()
Now, let’s chain these custom functions together and run them using PySpark DataFrame transform() function.
# PySpark transform() Usage
df2 = df.transform(to_upper_str_columns) \
.transform(reduce_price,1000) \
.transform(apply_discount)
Yields the below output.
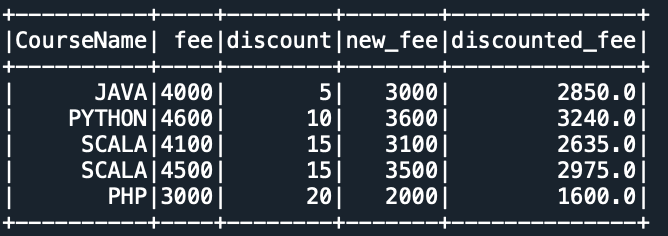
In case you wanted to select the columns either you can chain it with select() or create another custom function.
# custom function
def select_columns(df):
return df.select("CourseName","discounted_fee")
# Chain transformations
df2 = df.transform(to_upper_str_columns) \
.transform(reduce_price,1000) \
.transform(apply_discount) \
.transform(select_columns)
I will leave this to you to run and explore the output.
2. PySpark sql.functions.transform()
The PySpark sql.functions.transform() is used to apply the transformation on a column of type Array. This function applies the specified transformation on every element of the array and returns an object of ArrayType.
2.1 Syntax
Following is the syntax of the pyspark.sql.functions.transform() function
# Syntax
pyspark.sql.functions.transform(col, f)
The following are the parameters:
col– ArrayType columnf– Optional. Function to apply.
2.2 Example
Since our above DataFrame doesn’t contain ArrayType, I will create a new simple array to explain.
# Create DataFrame with Array
data = [
("James,,Smith",["Java","Scala","C++"],["Spark","Java"]),
("Michael,Rose,",["Spark","Java","C++"],["Spark","Java"]),
("Robert,,Williams",["CSharp","VB"],["Spark","Python"])
]
df = spark.createDataFrame(data=data,schema=["Name","Languages1","Languages2"])
df.printSchema()
df.show()
# using transform() function
from pyspark.sql.functions import upper
from pyspark.sql.functions import transform
df.select(transform("Languages1", lambda x: upper(x)).alias("languages1")) \
.show()
Yields below output.

3. Complete Example
Following is the complete example of PySpark transform() function
# Imports
from pyspark.sql import SparkSession
# Create SparkSession
spark = SparkSession.builder \
.appName('SparkByExamples.com') \
.getOrCreate()
# Prepare Data
simpleData = (("Java",4000,5), \
("Python", 4600,10), \
("Scala", 4100,15), \
("Scala", 4500,15), \
("PHP", 3000,20), \
)
columns= ["CourseName", "fee", "discount"]
# Create DataFrame
df = spark.createDataFrame(data = simpleData, schema = columns)
df.printSchema()
df.show(truncate=False)
# Custom transformation 1
from pyspark.sql.functions import upper
def to_upper_str_columns(df):
return df.withColumn("CourseName",upper(df.CourseName))
# Custom transformation 2
def reduce_price(df,reduceBy):
return df.withColumn("new_fee",df.fee - reduceBy)
# Custom transformation 3
def apply_discount(df):
return df.withColumn("discounted_fee", \
df.new_fee - (df.new_fee * df.discount) / 100)
# transform() usage
df2 = df.transform(to_upper_str_columns) \
.transform(reduce_price,1000) \
.transform(apply_discount)
df2.show()
# Create DataFrame with Array
data = [
("James,,Smith",["Java","Scala","C++"],["Spark","Java"]),
("Michael,Rose,",["Spark","Java","C++"],["Spark","Java"]),
("Robert,,Williams",["CSharp","VB"],["Spark","Python"])
]
df = spark.createDataFrame(data=data,schema=["Name","Languages1","Languages2"])
df.printSchema()
df.show()
# using transform() SQL function
from pyspark.sql.functions import upper
from pyspark.sql.functions import transform
df.select(transform("Languages1", lambda x: upper(x)).alias("languages1")) \
.show()
4. Conclusion
In this article, you have learned the transform() function from pyspark.sql.DataFrame class and pyspark.sql.functions package.
Related Articles
- PySpark map() Transformation
- PySpark mapPartitions()
- PySpark Pandas UDF Example
- PySpark Apply Function to Column
- PySpark flatMap() Transformation
- PySpark RDD Transformations with examples
- PySpark between() range of values
- PySpark max() – Different Methods Explained
- PySpark sum() Columns Example
- PySpark union two DataFrames
- PySpark Broadcast Variable
- PySpark Broadcast Join
- PySpark persist() Example
- PySpark Apply udf to Multiple Columns