
PySpark has several count() functions, depending on the use case you need to choose which one fits your need.
- pyspark.sql.DataFrame.count() – Get the count of rows in a DataFrame.
- pyspark.sql.functions.count() – Get the column value count or unique value count
- pyspark.sql.GroupedData.count() – Get the count of grouped data.
- SQL Count – Use SQL query to get the count.
By using the about count() functions you can get row count, column count, count values in column, get distinct count, get groupby count
1. Quick Examples
Following are quick examples of different count functions.
# Quick Examples of PySpark count()
# Get row count
rows = empDF.count()
# Get columns count
cols = len(empDF.columns)
print(f"DataFrame Dimensions : {(rows,cols)}")
print(f"DataFrame Rows count : {rows}")
print(f"DataFrame Columns count : {cols}")
unique_count = empDF.distinct().count()
print(f"DataFrame Distinct count : {unique_count}")
# functions.count()
from pyspark.sql.functions import count
empDF.select(count(empDF.name)).show()
empDF.select(count(empDF.name), count(empDF.gender)).show()
# using agg
empDF.agg({'name':'count','gender':'count'}).show()
# groupby count
empDF.groupBy("dept_id").count().show()
# PySpark SQL Count
empDF.createOrReplaceTempView("EMP")
spark.sql("SELECT COUNT(*) FROM EMP").show()
spark.sql("SELECT COUNT(distinct dept_id) FROM EMP").show()
spark.sql("SELECT DEPT_ID,COUNT(*) FROM EMP GROUP BY DEPT_ID").show()
Let’s create a DataFrame
# Import pyspark
from pyspark.sql import SparkSession
# Create SparkSession
spark = SparkSession.builder \
.appName('SparkByExamples.com') \
.getOrCreate()
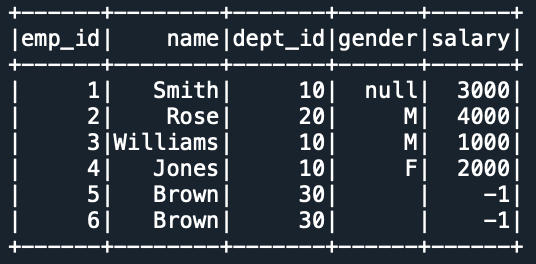
#EMP DataFrame
empData = [(1,"Smith",10,None,3000),
(2,"Rose",20,"M",4000),
(3,"Williams",10,"M",1000),
(4,"Jones",10,"F",2000),
(5,"Brown",30,"",-1),
(6,"Brown",30,"",-1)
]
empColumns = ["emp_id","name","dept_id",
"gender","salary"]
empDF = spark.createDataFrame(empData,empColumns)
empDF.show()
Yields below output
2. DataFrame.count()
pyspark.sql.DataFrame.count() function is used to get the number of rows present in the DataFrame. count() is an action operation that triggers the transformations to execute. Since transformations are lazy in nature they do not get executed until we call an action().
In the below example, empDF is a DataFrame object, and below is the detailed explanation.
- DataFrame.count() -Returns the number of records in a DataFrame.
- DataFrame.columns – Returns all column names of a DataFrame as a list.
- len() – len() is a Python function that returns a number of elements present in a list.
- len(DataFrame.columns) – Returns the number of columns in a DataFrame.
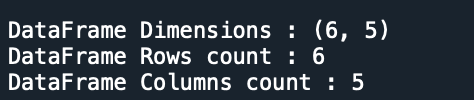
# Get row count
rows = empDF.count()
# Get columns count
cols = len(empDF.columns)
print(f"DataFrame Dimensions : {(rows,cols)}")
print(f"DataFrame Rows count : {rows}")
print(f"DataFrame Columns count : {cols}")
Yields below output.
2.1. Unique count
DataFrame.distinct() function gets the distinct rows from the DataFrame by eliminating all duplicates and on top of that use count() function to get the distinct count of records.
# Unique count
unique_count = empDF.distinct().count()
print(f"DataFrame Distinct count : {unique_count}")
3. functions.count()
pyspark.sql.functions.count() is used to get the number of values in a column. By using this we can perform a count of a single columns and a count of multiple columns of DataFrame. While performing the count it ignores the null/none values from the column. In the below example,
- DataFrame.select() is used to get the DataFrame with the selected columns.
- empDF.name refers to the name column of the DataFrame.
- count(empDF.name) count the number of values in a specified column.
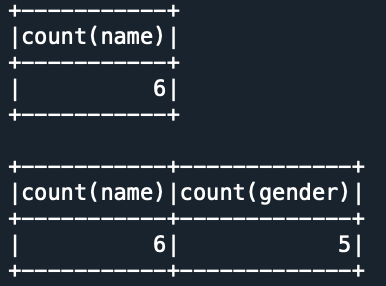
# functions.count()
from pyspark.sql.functions import count
empDF.select(count(empDF.name)).show()
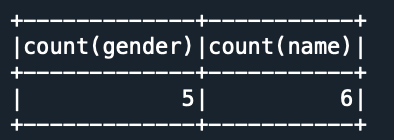
empDF.select(count(empDF.name), count(empDF.gender)).show()
Yields below output.
5. GroupedData.count()
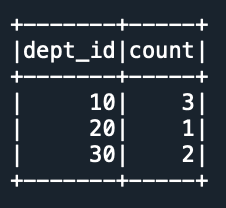
GroupedData.count() is used to get the count on groupby data. In the below example DataFrame.groupBy() is used to perform the grouping on dept_id column and returns a GroupedData object. When you perform group by, the data having the same key are shuffled and brought together. Since it involves the data crawling across the network, group by is considered a wider transformation.
Now perform GroupedData.count() to get the count for each department.
# Count on Groupped Data
empDF.groupBy("dept_id").count().show()
Yields below output.
6. Agg count
Use the DataFrame.agg() function to get the count from the column in the dataframe. This method is known as aggregation, which allows to group the values within a column or multiple columns. It takes the parameter as a dictionary with the key being the column name and the value being the aggregate function (sum, count, min, max e.t.c).
# Using agg count
empDF.agg({'gender':'count','name':'count'}).show()
Yields below output.
7. PySpark SQL Count
In PySpark SQL, you can use count(*), count(distinct col_name) to get the count of DataFrame and the unique count of values in a column. In order to use SQL, make sure you create a temporary view using createOrReplaceTempView().
To run the SQL query use spark.sql() function and the table created with createOrReplaceTempView() would be available to use until you end your current SparkSession.
spark.sql() returns a DataFrame and here, I have used show() to display the contents to console.
# PySpark SQL Count
empDF.createOrReplaceTempView("EMP")
spark.sql("SELECT COUNT(*) FROM EMP").show()
spark.sql("SELECT COUNT(distinct dept_id) FROM EMP").show()
spark.sql("SELECT DEPT_ID,COUNT(*) FROM EMP GROUP BY DEPT_ID").show()
Complete Example of PySpark Count
Following is the complete example of PySpark count with all different functions.
# Import pyspark
from pyspark.sql import SparkSession
# Create SparkSession
spark = SparkSession.builder \
.appName('SparkByExamples.com') \
.getOrCreate()
#EMP DataFrame
empData = [(1,"Smith",10,None,3000),
(2,"Rose",20,"M",4000),
(3,"Williams",10,"M",1000),
(4,"Jones",10,"F",2000),
(5,"Brown",30,"",-1),
(6,"Brown",30,"",-1)
]
empColumns = ["emp_id","name","dept_id",
"gender","salary"]
empDF = spark.createDataFrame(empData,empColumns)
empDF.show()
# Get row count
rows = empDF.count()
# Get columns count
cols = len(empDF.columns)
print(f"DataFrame Dimensions : {(rows,cols)}")
print(f"DataFrame Rows count : {rows}")
print(f"DataFrame Columns count : {cols}")
# distinct count
distinct_count = empDF.distinct().count()
# functions.count()
from pyspark.sql.functions import count
empDF.select(count(empDF.name)).show()
empDF.select(count(empDF.name), count(empDF.gender)).show()
# using agg
empDF.agg({'name':'count','gender':'count'}).show()
# groupby count
empDF.groupBy("dept_id").count().show()
# PySpark SQL Count
empDF.createOrReplaceTempView("EMP")
spark.sql("SELECT COUNT(*) FROM EMP").show()
spark.sql("SELECT COUNT(distinct dept_id) FROM EMP").show()
spark.sql("SELECT DEPT_ID,COUNT(*) FROM EMP GROUP BY DEPT_ID").show()
9. Frequently Asked Questions on count()
count() and countDistinct()? count() returns the total number of rows, while countDistinct() returns the number of distinct values in a column.
PySpark provides approxCountDistinct() for approximate distinct counting using the HyperLogLog algorithm, which can be faster for large datasets.
We can use groupBy and count() to count the occurrences of each value in a column.
For Example:
counts = df.groupBy(“column_name”).count()
isNull() or isNotNull() functions combined with count() to count the number of null or non-null values in a column. For Example:
null_count = df.filter(df[‘column_name’].isNull()).count()
non_null_count = df.filter(df[‘column_name’].isNotNull()).count()
8. Conclusion
In this article, you have learned different ways to get the count in Spark or PySpark DataFrame. By using DataFrame.count(), functions.count(), GroupedData.count() you can get the count, each function is used for a different purpose.
Related Articles
- PySpark Count Distinct from DataFrame
- PySpark sum() Columns Example
- PySpark count() – Different Methods Explained
- PySpark Groupby Count Distinct
- PySpark – Find Count of null, None, NaN Values
- PySpark isNull() & isNotNull()
- PySpark cache() Explained.
- PySpark Groupby on Multiple Columns
- PySpark Groupby Agg (aggregate) – Explained
- PySpark NOT isin() or IS NOT IN Operator
- PySpark isin() & SQL IN Operator