
We can get unique row values in Pandas DataFrame using the drop_duplicates() function. It removes all duplicate rows based on column values and returns unique rows. If you want to get duplicate rows from Pandas DataFrame you can use DataFrame.duplicated() function. In this article, I will explain how to get unique rows from DataFrame using the drop_duplicates() function and how we can also get unique rows based on specified columns with examples.
Related: You can drop duplicate columns from DataFrame.
1. Quick Examples of Get Unique Rows in Pandas
If you are in a hurry, below are some quick examples of how to get unique rows in DataFrame.
# Below are some quick examples
# Example 1: Use drop_duplicates() to get
# unique row values
df1 = df.drop_duplicates()
# Example 2: Set default param Keep = first
# get the unique rows
df1 = df.drop_duplicates(keep='first')
# Example 3: Set keep = last duplicate row & get unique row
df1 = df.drop_duplicates( keep='last')
# Example 4: Set keep param as False & get unique rows
df1 = df.drop_duplicates(keep=False)
# Example 5: Get unique rows based on specified columns
df1 = df.drop_duplicates(subset=["Courses", "Fee"], keep=False)
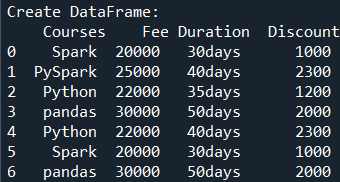
Now, let’s create a DataFrame with duplicate values, execute these examples, and validate the results. Our DataFrame contains column names Courses, Fee, Duration, and Discount.
# Create DataFrame
import pandas as pd
import numpy as np
technologies = {
'Courses':["Spark","PySpark","Python","pandas","Python","Spark","pandas"],
'Fee' :[20000,25000,22000,30000,22000,20000,30000],
'Duration':['30days','40days','35days','50days','40days','30days','50days'],
'Discount':[1000,2300,1200,2000,2300,1000,2000]
}
df = pd.DataFrame(technologies)
print("Create DataFrame:\n", df)
Yields below output.
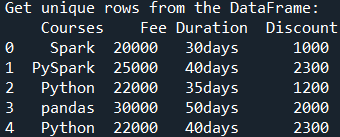
2. Pandas Get Unique Rows based on All Columns
Use DataFrame.drop_duplicates() without any arguments to drop rows with the same values matching on all columns. It takes default values subset=None and keep=‘first’. By running this function on the above DataFrame, it returns four unique rows after removing duplicate rows.
Related: You can get the first row from the Pandas DataFrame.
# Use drop_duplicates() to get
# Unique row values
df1 = df.drop_duplicates()
print("Get unique rows from the DataFrame:/n", df1)
# Set default param Keep = first
# Get the unique rows
df1 = df.drop_duplicates(keep='first')
print("Get unique rows from the DataFrame:\n", df1)
Yields below output.
3. Set Keep Param as Last & Get the Unique Rows
As we know from the above this function by default keeps the first duplicate. However, we can also keep the last duplicate by specifying the keep param as last.
Related: You can get the last row from the Pandas DataFrame.
# Set keep param last & get unique rows
df1 = df.drop_duplicates( keep='last')
print("Get unique rows from the DataFrame:\n", df1)
Yields below output.
# Output:
# Get unique rows from the DataFrame:
Courses Fee Duration Discount
1 PySpark 25000 40days 2300
2 Python 22000 35days 1200
4 Python 22000 40days 2300
5 Spark 20000 30days 1000
6 pandas 30000 50days 2000
4. Set Keep Param as False & Get the Pandas Unique Rows
When we pass 'keep=False' to the drop_duplicates() function it, will remove all the duplicate rows from the DataFrame and return unique rows. Let’s use this df.drop_duplicates(keep=False) syntax and get the unique rows of the given DataFrame.
# Set keep param as False & get unique rows
df1 = df.drop_duplicates(keep=False)
print("Get unique rows from the DataFrame:\n", df1)
# Output:
# Get unique rows from the DataFrame:
# Courses Fee Duration Discount
# 1 PySpark 25000 40days 2300
# 2 Python 22000 35days 1200
# 4 Python 22000 40days 2300
5. Get Pandas Unique Rows based on Specified Columns
We can also get unique rows based on specified columns by setting 'keep=False' and specifying the columns in the drop_duplicates() function, it will return the unique rows of specified columns.
# Get unique rows based on specified columns
df1 = df.drop_duplicates(subset=["Courses", "Fee"], keep=False)
print("Get unique rows from the DataFrame:\n", df1)
# Output:
# Get unique rows from the DataFrame:
# Courses Fee Duration Discount
# 1 PySpark 25000 40days 2300
6. Conclusion
In this article, I have explained how to get unique rows from Pandas DataFrame using the drop_duplicates() function with multiple examples. Also, I explained the usage of drop_duplicates() and how to use various parameters.
Happy learning!!
Related Articles
- Pandas Get List of All Duplicate Rows
- How to Drop Multiple Columns by Index in pandas
- How to get first row of DataFrame Pandas ?
- How to get last row of Pandas DataFrame?
- How to append DataFrames using for loop?
- How to get first N rows of DataFrame?
- Get row number in Pandas DataFrame
- How to drop first row from the Pandas DataFrame?
- Drop DataFrame rows by index
- How to add/insert row to Pandas DataFrame?
- Pandas get the number of rows from DataFrame
- Pandas Drop Rows Based on Column Value
- Pandas compare two DataFrames row by row
- Difference between two DataFrames
Reference
https://pandas.pydata.org/docs/reference/api/pandas.DataFrame.drop_duplicates.html