
Why Delta Lake? In modern-day big data projects, there are many cloud object data lake storages such as Amazon S3 and Azure Data Lake are some of the largest and most cost-effective storage systems. Unfortunately, their implementation as key-value stores makes it difficult to achieve ACID transactions, high performance, and cross-key consistency, and Metadata operations such as schema enforcements, and listing objects are expensive and consistency guarantees are limited. To take over these limitations delta lake is introduced.
In this article, we will discuss Delta Lake in Databricks and its advantages.
Table of contents
1. What is Delta Lake?
Delta Lake is an open-source storage layer that enables building a data lakehouse on top of existing storage systems over cloud objects with additional features like ACID properties, schema enforcement, and time travel features enabled.
Underlying data is stored in snappy parquet format along with delta logs.
It supports both Batch and Streaming sources under a single platform in Databricks.
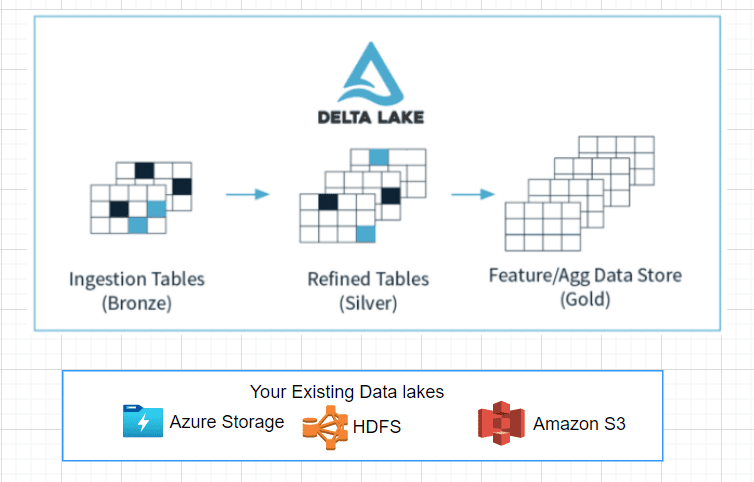
2. Features of Delta Lake
2.1. Added ACID Properties:
ACID properties are the ones that define a transaction (Atomicity, Consistency, Isolation, Durability). They help us in guaranteeing the below.

- Atomicity: Makes sure each transaction(to read, write, update or delete data) was completed all at once or doesn’t happen at all. This helps in preventing data loss and data quality issues.
- Consistency – ensures the data objects are consistent before and after transaction.
- Isolation – enables transactions to ensure that inter collation is not happening in-between transactions and provides ordering among transactions. It makes possible to read and append when there is an update going on.
- Durability – ensures that transactions on your data made successfully will be saved, even in the event of system failure.
Note: ACID properties ensure that your data never falls into a bad data quality state because of a transaction that was only partially completed or failed and provide data reliability and integrity.
2.2. Schema enforcement
When we write data into Delta Lake, it also stores the schema of your data in JSON format inside the transaction log. Delta Lake uses these JSON files for schema validation in the subsequent writes. By default, It compares your existing schema with the incoming schema and if any mismatches are found then it makes the entire transaction fail. This is one of the features that provides schema evaluation and data quality
In case of schema changes between existing and incoming data, we can handle the failure due to mismatch by merging the schema changes. To achieve this we have to enable auto-merge in the spark configuration or add mergeSchema option as true while writing the dataFrame.
//Enabling autoMerge in spark configuration
spark.conf.set("spark.databricks.delta.schema.autoMerge.enabled","true")
OR
//mergeSchema to true while writing dataFrame
dataFrame.write.format("delta")
.option("mergeSchema", "true")
.mode("append")
.save(DELTALAKE_PATH)
2.3. Time Travel
All the changes on a table in Delta Lake were tracked, stored in delta logs, and resulted in a newer version of that dataset. Whenever we query the table it showcases the latest version of it. It also uses this versioning concept to track and revert back to previous versions for Audits and rollbacks in Databricks.
To deep dive more into time travel, please have a look at this article Time Travel with Delta Tables in Databricks?
2.4. UPSERT Operations
Delta Lake supports upsert (Insert or Update) operations on the existing datasets by comparing changes in existing data with the incoming data and ensuring no duplicates were inserted based on the primary keys used.
MERGE INTO table1 a
USING table2 b
ON a.column_x = b.column_y
WHEN MATCHED THEN
UPDATE SET
column_a = b.column_p,
column_b = c.column_q,
........
........
WHEN NOT MATCHED
THEN INSERT (
column_a,
column_b,
......,
......,
......
)
VALUES (
b.column_p,
b.column_q,
b.column_r,
..........,
..........
)
3. Problems solved by Delta Lake
- Complexity in appending data to existing dataset reduced.
- Difficulty in modification of existing data was reduced.
- Ensure data consistency and quality even after jobs fail midway.
- Real-time operations were easy.
- Decrease in Cost to keep historical data versions.
4. Delta Lake is Not
- Proprietary technology
- storage format
- storage medium
- Database service or data warehouse
5. Delta Lake is
- Open-source.
- Builds upon standard data formats: It is powered primarily by parquet format.
- Optimized for cloud object storage.
- Built for scalable metadata handling.
6. Conclusion
The primary objective of delta lake is resolving the time taken for quickly returnable queries and providing data consistency even on Upsert operations. Delta Lake decouples storage and computing costs and provides optimized performance on data.